|
2023年6月15日,英特尔宣布将对自己的移动平台酷睿处理器进行「品牌升级」,移动平台中非性能处理器(即非HX处理器)被命名为intel Core X(3/5/7)或者intel Core Ultra X(3/5/7),其中采用Raptor Lake架构的小改款名字不带Ultrta,而采用新一代Meteor Lake结构的新平台名字中带有Ultra。由于Core X和Core Ultra X目前都还是第一代产品,因此这个产品线的中文名分别叫「英特尔酷睿第1代处理器」和「英特尔酷睿Ultrta第1代处理器」。
虽然英特尔表示移动平台高性能处理器和桌面端处理器暂时原本的品牌名,但不少玩家都认为英特尔会趁着桌面14代酷睿的时间点,一并更换桌面处理器的品牌名,从而实现品牌名称的统一。
图片来源:英特尔
当然了,这些也都可能只是英特尔的释放的障眼法,其目标是让大家把注意力放到英特尔产品的名字,而不是14代酷睿采用的Raptor Lake上。但无论英特尔怎么想,留给他们的时间已经不多了。一方面,按照英特尔的更新节奏,新一代桌面酷睿最快10月份就要跟我们碰面了。另一方面,根据网上关于14代酷睿的爆料,14代酷睿的配置并没有大家预想中那么好。
13代酷睿的威力增强版?
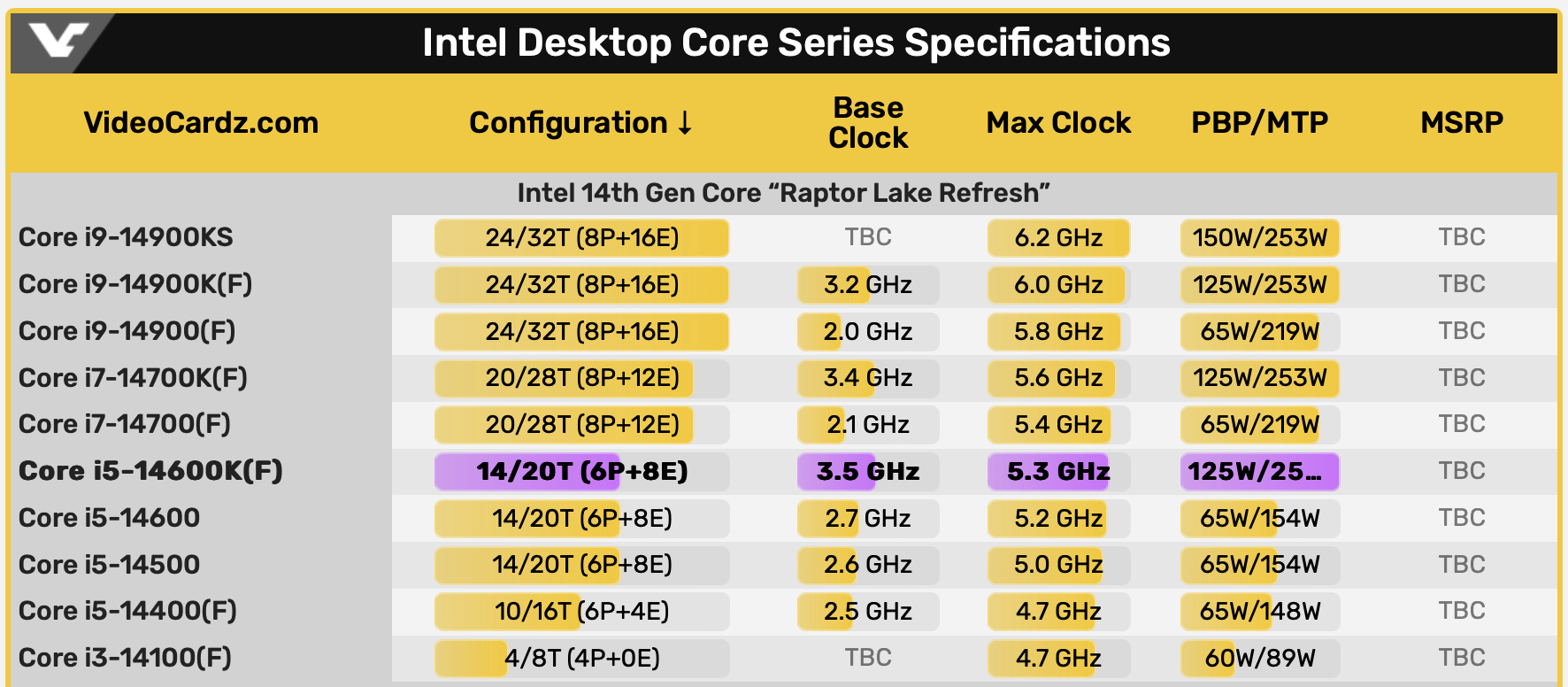
在最开始的「爆料」中,14600系列处理器将从原本的6P4E配置升级为和13700相同的8P8E配置,最大睿频也将提升到5.2GHz。如果该消息属实,这意味着新14代i5可以在不需要算法优化、仅凭借硬件配置的情况下追平13代i7处理器,同时还拥有更好的功耗控制。但在前段时间爆出的CPU-Z截图中,被我们寄予厚望的14600K依旧采用了6E8P、14核心配置,L3缓存也依旧停留在24MB而不是最初爆料的30MB,仅最大睿频提升到5.3GHz。
图片来源:VideoCardZ
值得注意的是,截图中配合14600K测试的主板南桥并不是传说中「Z890」而是「Z790」,且插槽也是当前12代、13代酷睿所使用的LGA 1700插口。接口不换、配置不换、制程工艺也都还是10nm、仅频率略微上调,说实话英特尔这样很难让人相信全新的14代桌面酷睿本质上不是13代、甚至是12代酷睿的「威力增强版」。
除了14600K的参数外,VideocardZ也发布了所谓的LGA1700接口生态图:14代依旧分为i9/i7/i5/i3四个等级,其中i9提供900/900K/900KS三种型号,均采用8P16E的核心配置,最大睿频依次为5.8GHz/6.0GHz/6.2GHz,和13代的版本相比各提升了200MHz。
如果最终发布的14代处理器表现真如VideocardZ的汇总表所猜测的那样,那至少证明了两件事:一是英特尔在12代酷睿中提出的「大小核」概念确实非常超前,二是英特尔未来很可能又得在邀请函里放一管高露洁牙膏了。
英特尔的底气在哪里?
从好的方面看,英特尔即使真的在14代酷睿上挤牙膏,也没有像Apple那样在新一代处理器的关键性能上动刀、让新产品的读写性能还不如上一代的老产品,甚至在最大睿频上还有些许提升到,为消费者带来了200MHz的官方超频。
再说了,借助12代、13代两代酷睿,英特尔已经证明了「一般用户并不在意硬件上实打实地升级,反而更在意那些抽象化的虚拟指标」,比如运算性能提升、基于新编码获得的编解码效率提升、以及更重要的AI性能。要知道英特尔发布的新一代至强W处理器采用的可是实打实的全P核配置,换句话说,英特尔非常清楚对性能有要求的工作站用户究竟需要怎样的处理器。
图片来源:英特尔
但英特尔依旧愿意在酷睿处理器中采用「大小核」的方案,这其实也从市场反馈的角度证明了一般用户并不需要「性能超群」的处理器,他们需要的仅仅是「优秀的性能表现」。至于这个优秀的性能表现来自更高成本的硬件堆砌?还是来自更智能的AI算法,比如英特尔ITD(Intel Thread Director)。
换句话说,是AI技术给了英特尔挤牙膏的底气。
无论是英特尔还是英伟达,在这几年都开始强调利用AI技术提高硬件的性能表现。在最初,这种做法被认为是品牌的硬件红利已经到头,希望用成本更低的AI技术突破硬件的制程限制,用更低的成本实现性能的飞跃。
5月底,英伟达公布了最新一季财报,在游戏和专业可视化收入继续大跌的背景下,数据中心收入达到创纪录的42.8亿美元。电话会议上,黄仁勋解释说:
计算机行业正在同时经历两种转变——加速计算和生成式AI。随着各个公司竞相为生成式AI部署加速计算,价值1万亿美元的全球数据中心基础设施将从通用计算转向加速计算。
这种转变不仅发生在数据中心,还发生在全世界的PC和智能手机上。早前的一场媒体会上,英特尔就在一台轻薄笔记本上展示了通过本地运行Stable Diffusion生成图片的过程。
英特尔客户端计算事业部终端生态合作亚洲区总监高源透露,新一代Meteor Lake处理器将会集成CPU、GPU以及专门面向AI加速的独立计算单元VPU。不仅如此,CPU、GPU以及VPU将共同参与AI加速计算的过程,使得在轻薄型PC成为可能。
图片来源:英特尔
换句话说,无论笔记本还是台式机,未来都一定会和AI技术产生交集。唯一的不确定性是在AI时代,个人电脑将以怎样的身份加入到AI体系当中。是完整的算力中心?可以连接云端算力的边缘节点?还是退化成一个只用来与AI发生交互的终端载体呢?
本地化AI打破摩尔定律?
出于对个人数据的考量,小雷其实更希望将关键的AI数据以离线方式保存在本地。这一方面是为了保证个人数据不会连接到互联网,另一方面也是考虑到网络连接的不确定性。要知道现在的5G网络就连几个智能灯泡都搞离线,我不敢想象在云端「拉闸」的情况下,基于AI运行的计算机系统是否还有运作的可能。
再说了,同时AI作为一种基础设施,未来应该被所有人使用,使用场景也将极其广泛,包括轻负载和重负载场景,也包括对延时比较敏感的场景。而从数据传输到云端处理,再回传结果,其中必然会有网络延时的影响,一些AI任务可能不需要过高的加速性能,反而要求更低的延时。
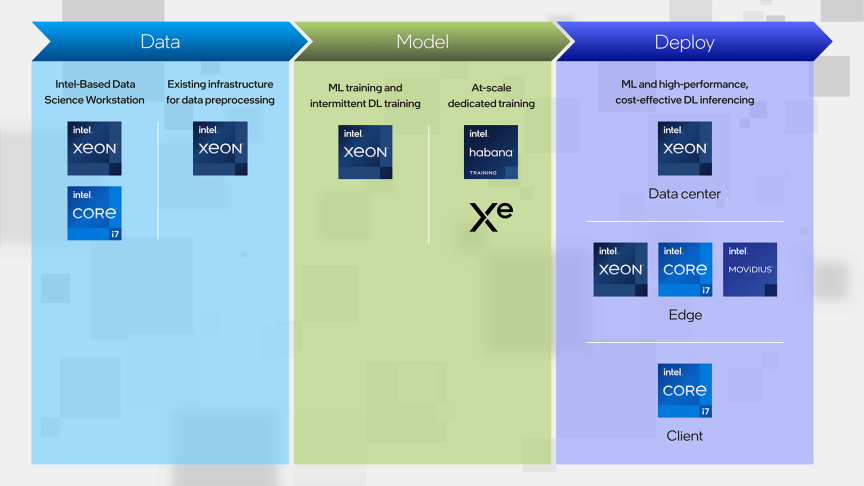
图片来源:英特尔
一言以蔽之,来自云端的算力无法覆盖更多的AI使用场景,也满足不了更多人的AI使用需求,AI不可能只「活」在云端。这一点在英特尔给出的「AI生态图」中也有所展示:「Deployt」(部署)分类下,酷睿i7同时出现在了Edge(边缘计算)和Client(客户端)两栏中。
在前不久结束的Computex上,高通资深副总裁暨运算及游戏部门总经理Kedar Kondap说,考虑到延时、效率和实用性等问题,部分计算于手机、平板或电脑中、部分则在云端运行,「未来的AI计算是混合的。」
可以肯定的是,为AI提供算力支持一定会是个人电脑接下来的发展重点,而基于AI二次开发出的全新应用场景也会从场景侧反过来弥补硬件侧的技术短板,甚至让芯片发展跳出「摩尔定律」的限制,用算法为硬件带来更多的可能性。
| 

![群星《上华世纪总冠军》4CD[低速原抓WAV+CUE]](data/attachment/block/91/91c5de3ffddde703f48ba7023c17e685.jpg)
![曼里《爱有天意》2023头版限量编号24K金碟[WAV+CUE]](data/attachment/block/63/63fe232c9367173c0c901a4a1fe31647.jpg)
![曹滟莉2023 - 粤语经典 古筝专辑 [WAV+CUE]](data/attachment/block/3b/3be071f904b31054f9361713bcb8b988.jpg)
![张炜《依然爱你》发烧女声DSD版[WAV+CUE]](data/attachment/block/65/659e699c55df84f3cd3b0c10ee121022.jpg)